- awesome MLSS Newsletter
- Posts
- Is an image worth a thousand words for AI? - Awesome MLSS Newsletter
Is an image worth a thousand words for AI? - Awesome MLSS Newsletter
13th Edition
Awesome MLSS
January 29, 2026

We all think, whether or not we speak a language. Plenty of creatures adapt to situations without needing explicit encoding via language. However, our current AI models focus on conversion to language before any analysis can begin.
Reasoning models are trained on a self induced loop of thoughts, each thought decoded autoregressively. This poses several issues - recent papers [1] [2] highlight how much influence the first few tokens have on the rest of the generation, pushing the final output into increasingly orthogonal spaces.
A new paper from Meta FAIR discusses a novel architecture to allow models to ‘see’ the world not in discrete outputs, but by using the underlying semantic structures. More on this, after a few updates.
Upcoming Summer School Announcements
Applications for some of the following summer schools are closing in the next 10 days. Make sure to apply to them before the application deadline!
Title | Deadline | Dates |
|---|---|---|
Robotics, Perception and Learning (RPL) Summer School 2026 - Stockholm, Sweden | Feb 8 | Jun 21 - Jun 26 |
Mar 01 | Jun 15 - Jun 19 | |
Apr 07 | 7 May - 16 May |
For the complete list, please visit our website
What’s happening in AI?
Yann LeCun, Turing laureate, former Chief Scientist at Meta FAIR, and one of the godfathers of AI, disagrees with the current direction of research in the field. He has publicly stated that autoregressive LLMs will not be the path to AGI
His key argument is simple - LLMs lack the ability to form world models, and contain hallucinations as a feature. To this end, he focused his research on a new architecture called JEPA (Joint Embedding Predictive Architecture).
JEPA models focus on creating thought patterns not in a discrete token space, but rather in a latent space with embeddings, and are trained similarly. LeCun’s latest paper, VL-JEPA, is an effort to use JEPA with vision to enable vision understanding for general purposes.
The Core Problem
Current Vision Language Models (VLMs) take images and a textual query, project them into a shared latent space, and then autoregressively decode tokens one at a time to provide outputs in text format. This is incredibly inefficient, since in most videos not much changes per frame, but irrespective of that, the whole model must make multiple passes for generation.
Then there is the issue of orthogonality in token space. Consider a question posed to a robot looking at a switch - what happens if the switch is turned off? The answers “the light goes out” and “the room goes dark” are both correct, but since the two are orthogonal in the token space, the model may or may not look at both possibilities.
How VL-JEPA Solves This
VL-JEPA takes images and text input, projects them into a shared latent space, and processes them. This part is the same as above. However, VL-JEPA does not autoregressively decode the output. It instead provides embeddings alone, with the complete training mechanism focused on generating embeddings that align with a text encoder.
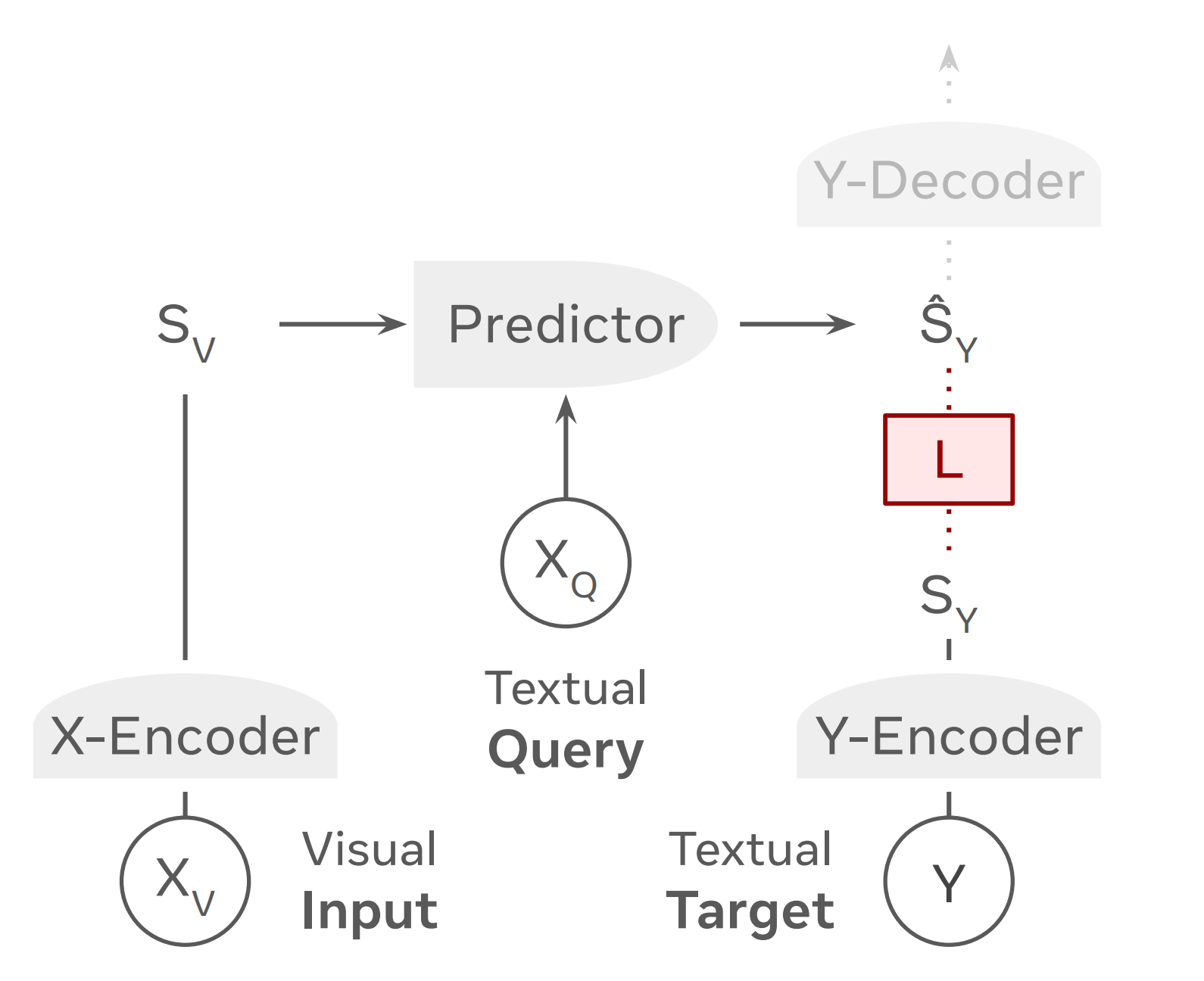
Overall Model Architecture of VL-JEPA. Image Source: https://arxiv.org/pdf/2512.10942
These embeddings are faster to process, since they only require one forward pass, as opposed to the multiple steps in autoregressive decoding. The model uses a small text decoder (which is not a part of training) to decode the embeddings to text as and when required.
For instance, if a robot is constantly looking at a white wall while stationary, we would be wasting precious resources continuously decoding text. With VL-JEPA, these tokens would not all be decoded. Now, if the white wall is suddenly splashed with red paint, there is new information to process, and the embeddings are decoded. The mechanism for selecting when the decoding will happen intuitively looks at variance in the embedding stream - if there is large variation, there is new information to be processed, and only that sequence is decoded to text. The precise mechanism is described in section 4.5 of the paper titled “Effectiveness of selective decoding”
Since we focus purely on latent information, we are now dealing with similarity not in orthogonal token space but in the embedding space, which allows highly similar concepts to be closer. This way, from our previous example, “the light goes out” and “the room goes dark” are both features that will be encoded into the output.
In fact, for similar performance compared to VLMs, VL-JEPA uses half the parameters, and reduces the decoding operations by almost 2.85X! This makes it better suited for low latency processing.
Architecture and Training
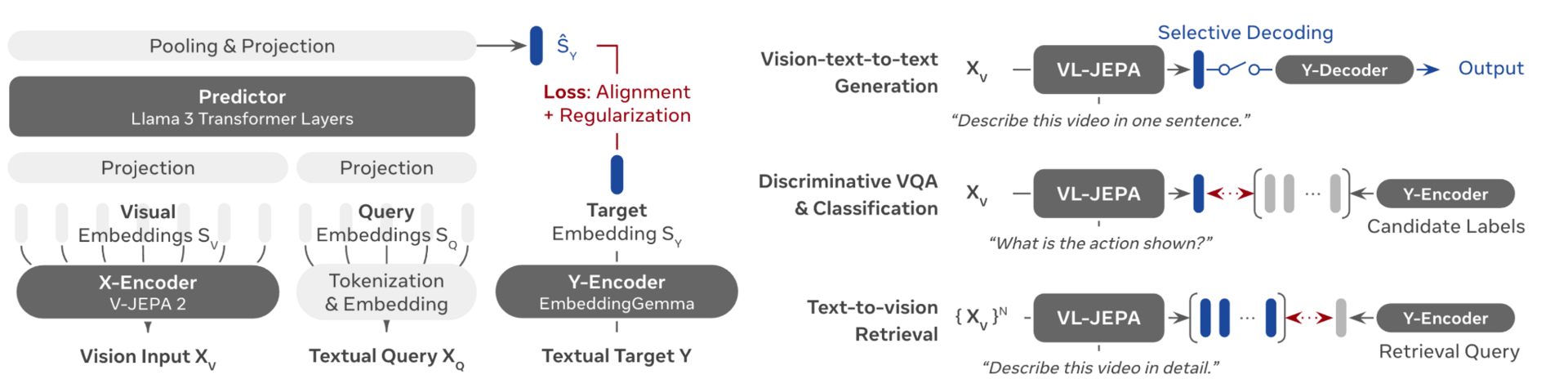
VL-JEPA Architectural Details, and task specific execution. Image Source: https://arxiv.org/pdf/2512.10942
VL-JEPA first encodes images into embeddings using an image encoder, initialised by V-JEPA 2 ViT-L, a vision transformer with 304M parameters. This is referred to as the X-Encoder. Then, the text based query is encoded into embeddings.
Outputs from the two encoders are projected into a Predictor network, initialised by the last 8 layers of Llama 3.2-1B. Bear in mind, the causal attention mask is removed to allow intermixing of text and image tokens. The predictor layer then outputs multiple embeddings, which are finally pooled and projected. This gives us the final output embedding.
In order to train the model, the output embeddings are aligned with the Y-Encoder that takes the output target text as input, and loss is calculated against the final output embedding seen above. This is initialised by EmbeddingGemma-300M.
The loss function must both predict error in embedding space, and prevent representation collapse, to which end the authors choose InfoNCE Loss as the loss function.
Experimental Results
On tasks related to classification and retrieval, VL-JEPA Base (trained only on image/caption pairs and not query texts) shows higher average accuracy and recall across the 8 datasets they tested on. In particular, the model performs best on motion-centric benchmarks and step recognition as compared to appearance centric ones. The authors ascribe this to the fact that the model has seen far fewer images (2B compared to PE-Core-G’s 86B).
VL-JEPA SFT (Base model finetuned on visual question answering with both image and text pairs), despite being a generalist model, seems to reach the same performance levels as specialist models dedicated to each task.
For Visual Question Answering tasks, VL-JEPA SFT outperforms most models of up to between 2B to 72B parameters, despite only having 1.6B parameters itself!
On the WorldPrediction-WM benchmark, the model is provided with two images representing the initial and final world states. The task is to identify which among four candidate video clips best explains the transition between these two states. VL-JEPA Base achieved 63.9% accuracy, while VL-JEPA SFT achieved 65.7%, establishing a new state of the art. The authors note that it outperforms not only existing VLMs, but also frontier LLMs such as GPT-4o, Claude-3.5-Sonnet, and Gemini 2.0.
The authors also sought to analyse the gap between embedding prediction and token prediction. To this end, they fine tuned two models - one based on the backbone of typical VLMs, the other on VL-JEPA, with all the base models such as vision encoder, predictor network, learning rate, dataset etc. kept the same. They then evaluated the performance gap between the models at regular checkpoints between 500K to 15M samples seen.
At 500K samples, both models seem to perform similarly. However, after a few more iterations, VL-JEPA considerably outperforms the VLM, the results of which are available in section 4.4 of the paper, titled “Embedding Prediction vs. Token Prediction: A controlled comparison”. The authors also note that VL-JEPA had half the trainable parameters.
To understand the benefits of selective decoding, the authors construct a benchmark where the goal is to recover a temporal sequence of annotations while minimising the number of text decoding operations.
As a baseline, they use uniform sampling, i.e. placing decoding points at fixed intervals regardless of the underlying video content. Current streaming VLMs use this strategy. VL-JEPA however uses adaptive selection of decoding points, which uses agglomerative clustering to partition the output embedding sequence into segments of high intra-segment similarity, measured by variance such as Ward Distance. The underlying intuition is that we only need to decode once for each segment that is very similar to other embeddings within itself, reducing the overall cost of decoding. The decoding might be performed on the midpoint or the average pooled embedding.
They vary the decoding frequency from 2.0 Hz to 0.01 Hz, and note that across the range, adaptive selection consistently Pareto-dominates uniform sampling. Selective decoding at 0.35 Hz in particular matches the performance of uniform decoding at 1 Hz, provably reducing decoding cost by 2.85x.
Conclusion
As a much smaller, and generalist model, VL-JEPA shows incredible promise in world model understanding. Instead of focusing on token space, and rather relying on latent space, VL-JEPA also proves that underlying semantics are captured better, leading to more reliant and understanding models. This is clearly demonstrated by the superior performance.
Owing to its embedding based architecture, VL-JEPA is also able to perform cross modal operations such as open vocabulary classification and cross model retrieval. This design also allows it to be better suited for low latency real time video understanding, which could greatly benefit multiple fields, especially robotics.
There is yet work to be done, however. The authors note that this is not yet a universal alternative to VLMs, since there are many other angles to consider such as reasoning, tool use, agentic behaviours, etc. where token based VLMs shine. Additionally, while they noticed benefits from scaling parameters and dataset size, they have left this work for the future.
Awesome Machine Learning Summer Schools is a non-profit organisation that keeps you updated on ML Summer Schools and their deadlines. Simple as that.
Have any questions or doubts? Drop us an email! We would be more than happy to talk to you.
Reply