- awesome MLSS Newsletter
- Posts
- Paying Attention to Attention- Awesome MLSS Newsletter
Paying Attention to Attention- Awesome MLSS Newsletter
16th Edition
Awesome MLSS
March 11, 2026

Ever since transformers were devised in 2017, attention heads have become a central part of all our AI efforts. Optimising them, caching them, improving their long range abilities. They are the prima donnas of the GenAI show.
In terms of interpretability, however, we are still trying to understand exactly how they work. If we attend to a token, why do we attend to it, and how do these transformations take place?
A recent paper, Decomposing Query-Key Feature Interactions Using Contrastive Covariances analyzes how queries and keys interact in their joint embedding space. Before we dive into it, we call attention to some updates.
Upcoming Summer School Announcements
Applications for some of the following summer schools are closing in the next 30 days. Make sure to apply to them before the application deadline!
Title | Deadline | Dates |
April 7, 2026 | May 7 – May 16, 2026 | |
May 15, 2026 | June 22 – June 26, 2026 | |
Oxford Machine Learning Summer School – MLx HEALTH & BIO 2026 — Oxford, UK | May 22, 2026 | July 10 – July 13, 2026 |
OxML 2026 – MLx Representation Learning & Generative AI 2026 — Oxford, UK | May 22, 2026 | July 15 – July 18, 2026 |
For the complete list, please visit our website
What’s happening in AI?
First, let’s get a core intuition for what the attention layer is doing. To refresh your memory, we recommend reading these blogs by Lilian Weng and Jay Alammar. Here is the formula for attention, where Q, K, and V are projections of the token embeddings.
Attention(Q, K, V) = softmax((Q @ K.T) / sqrt(d_k)) @ VAttention first calculates attention scores using query and key projections on the token embeddings, and then the output matrix is multiplied with the value projections. What does each do?
Query - this projection is the query being asked. For instance, it may ask “which of these tokens is an animal”
Key - this projection in essence creates a lookup table, and tells the query which token might resolve it
Value - the actual information carried by the token. The query and key determine which tokens matter; the value determines what gets passed forward from them. The combination of the value projection and output projection learns how to extract the correct token embedding information.
None of this is explicitly encoded into the projections. The manner in which the equation is laid out, and the training procedure ultimately give rise to these separation of concerns.
This paper focuses on analyzing the QK interactions, and provides a method to perform causal interventions on decomposed QK vector spaces.
Unless otherwise mentioned, all credits for images in this newsletter go to the original paper available at: https://arxiv.org/pdf/1709.06716
Intuition Behind the Paper
Decomposing Query-Key Feature Interactions Using Contrastive Covariances is a pretty self explanatory name, and they do exactly that. The fundamental idea is to separate the query vector subspace and key vector subspace, then analyze them using contrastive covariances. Let’s develop an intuition for this.
Ultimately, all projections are created by doing a matrix multiplication. This means the token embeddings were linearly transformed into a different vector space. In essence, the query and key projections take in embeddings, and then output an equivalent structure in their own vector spaces, which then interact to create a joint embedding space.
We could directly analyse the query and key projections, but they are extremely high dimensional, and are not human readable.
There are several mathematical tools for analysing linear transformations, the most common ones are Singular Value Decomposition and Principal Component Analysis. For further reading, we recommend the MML Book’s section 4.5 (SVD) and chapter 10 (PCA)
Crux of the matter is, we would like to be able to take the output of a transformation, and split it into three separate features - the transformation in the input space, transformation in the output space, and the eigenvalues of the transformation (i.e. the magnitudes of transformation along the directions. Refresher on eigenvalues).
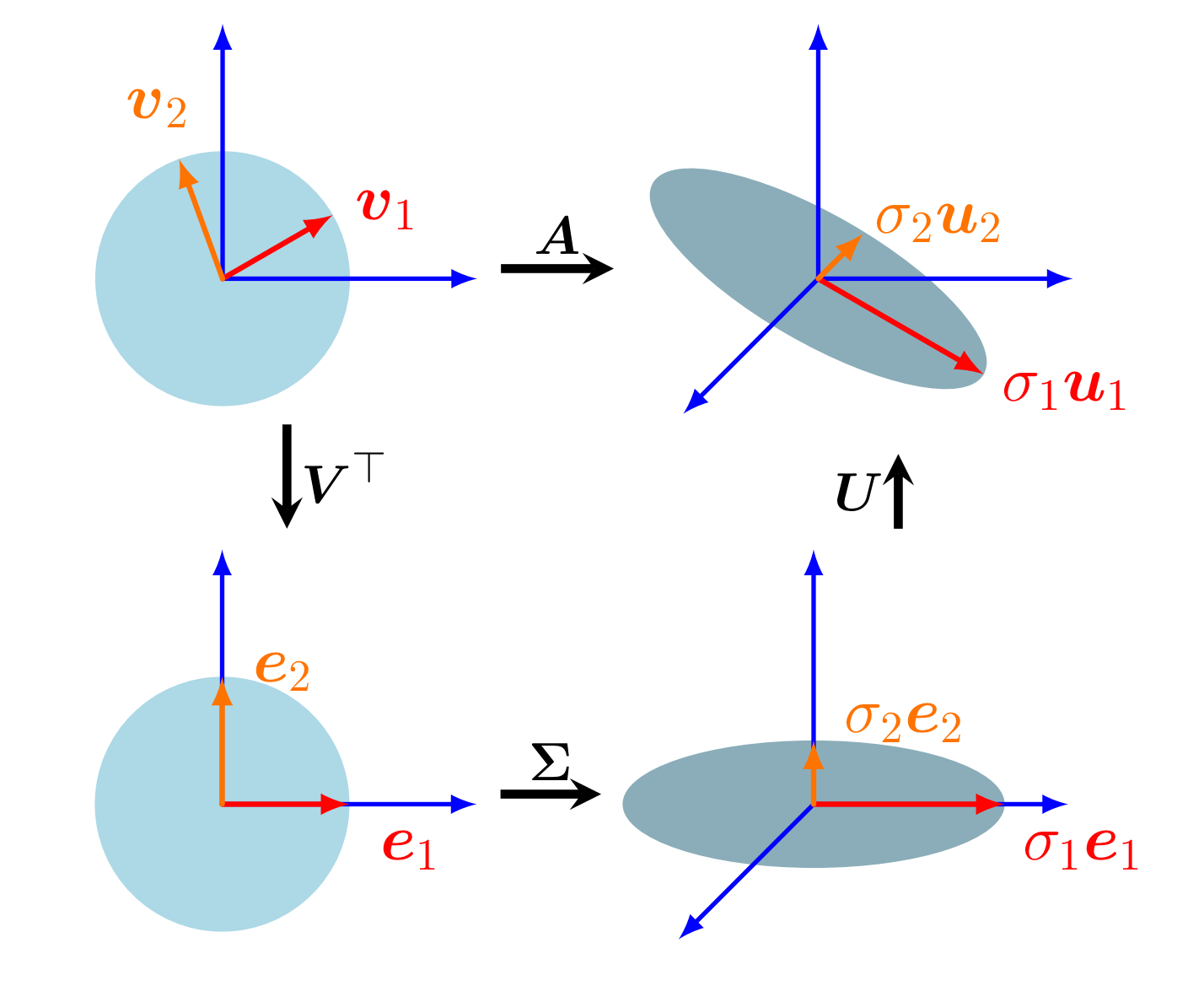
Geometric intuition for SVD - Vectors v1 and v2 of input space are transformed by A. We decompose the transformation into three components to analyze it. Image credits: Figure 4.8 of MML Book
In our case, our input space is the query projection subspace, and the output space is the key projection subspace. The eigenvalues found via the SVD tell us which directions are most important for moving along either subspace.
Now, knowing this is valuable, but what we really want to know is how much it matters if we change the keys to some different value for the same query, for which we use contrastive covariances - let’s start looking at the paper’s formulation now.
The Method
The authors propose a new way to analyze QK interactions. They introduce latent variables in the embeddings to be able to isolate the effects of each. The model is a simple attention layer, similar formulation as above. It’s the embeddings that are changed.
The embeddings are decomposed into K latent variables to analyze and isolate each decomposed variable’s impact. If we chose only one latent variable, we would be able to isolate the subspace, but we would not be able to understand how the model actually decomposes features. The authors choose K = 2 for simplicity, which they mention in their experimental design
Each embedding is constructed from three components: two latent variables z1 and z2 (binary sign vectors of length r1 and r2 respectively), and a payload — the one-hot encoding of the token's class label. All three are projected into the embedding space via fixed random linear maps, giving:
x_i = A₁z₁,ᵢ + A₂z₂,ᵢ + A_y·e_yᵢ + εThe selector embedding is constructed similarly, using the same latent variables z1 and z2 as the target token — but projected with different matrices B1 and B2, and without any payload information:
x_q = B₁z₁,ᵢ* + B₂z₂,ᵢ* + εqEpsilon in both cases is random gaussian noise to simulate real world data.
The task is then straightforward to state but non-trivial to solve: the selector and its target share the same underlying latent structure, but expressed in different bases. The attention head must learn to bridge that gap and retrieve the correct payload without any shortcut from the selector, which carries no payload of its own. The attention equations remain the same, and we calculate cross entropy loss for training
Contrastive Covariances
What we want to analyze is the contrastive covariance between queries and keys that isolates their interactions related only to one latent variable. For this, the authors hold the query fixed, while changing only one of either z1 or z2 for the key value of the correct payload embedding, holding the other z value constant.
What this does, is isolate the effect of z1/z2 on the selection of the correct payload embedding. The key values with correct z1/z2 are k+, while those with incorrect are k-. With sufficient (q, k+, k-) triplets, we can construct covariance matrices for positive and negative k values as follows:
C + (z1) := E[qk⊤|+] ∈ R dhead×dhead C − (z1) := E[qk⊤|−] ∈ R dhead×dhead For above, we only change z1 to create k- samples, z2 remains the same. The contrastive covariance matrix then becomes
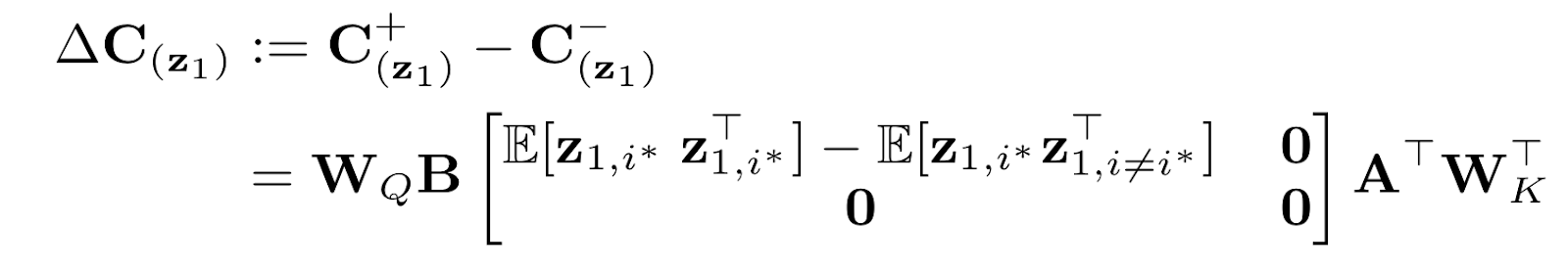
where B := [B1, B2] and A := [A1, A2] and i * is the timestep of the query. The full derivation is provided in the paper. This gives us the SVD form, where we can isolate the effects of Wq and Wk.
∆C(z₁) = U(z₁) Σ(z₁) V⊤(z₁)The rank r₁ is estimated by counting the number of singular values that capture 99% of the squared Frobenius norm of ∆C(z₁). The top-r₁ singular vectors U:r₁ and V:r₁ then give a basis in query space and key space respectively that encodes z₁. This is repeated for each latent variable to recover their ranks and subspaces.
Empirical Analysis
With the mathematical theory in place, the authors now test their assertions on a toy attention model.
Recovery of Subspace Ranks
First, the authors verify that their formulation faithfully recovers the ranks of the latent variables. For this, they train their toy attention model with varying values of each parameter. Details are available in section 4 of the paper.
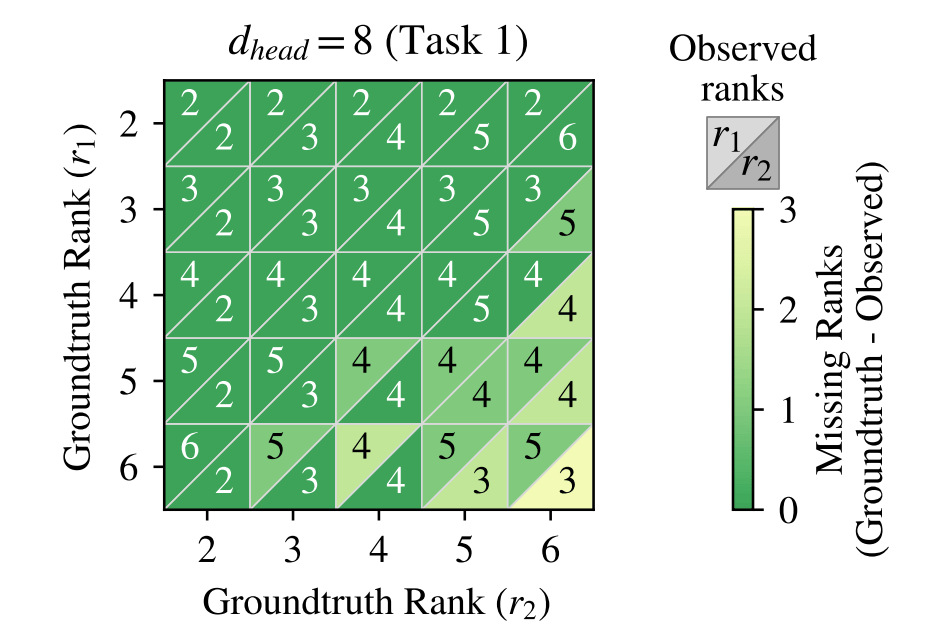
In all cases, as long as r1 + r2 < d(head), their formulation correctly finds the ranks of the subspaces. However, when that is not the case, there are missing ranks - this is attributed to superposition (which we discussed in detail in one of our prior newsletters, Does scaling have a ceiling?)
The intuition is that the dimensions of the head did not have enough latent variables to assign an independent direction to each variable of the latent space and combined multiple features into one, reducing the rank of the projection. This was also empirically verified.
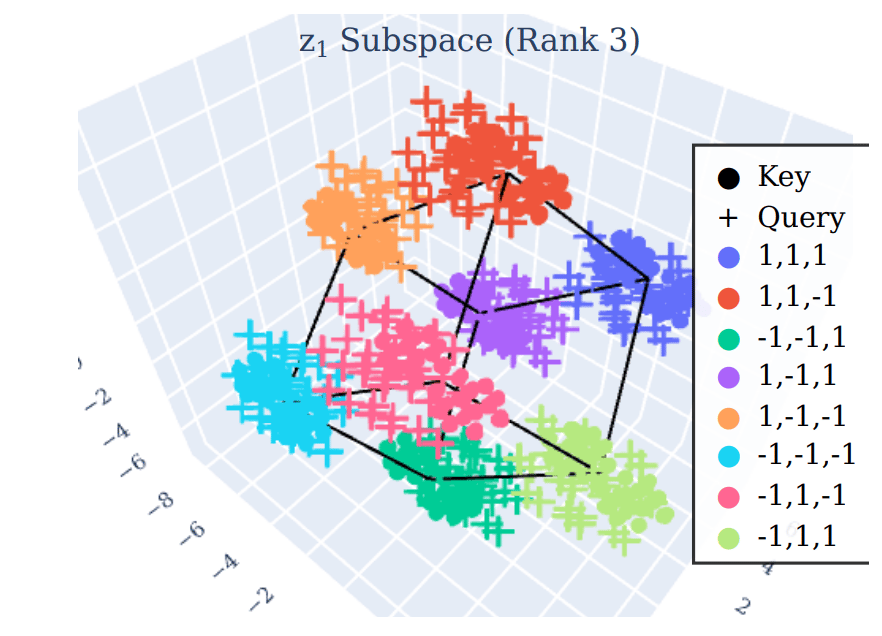
Recovering Latent Variables in QK Space
Empirically, the projection of the query and key values into the reduced U:r1 and V:r1 should retrieve the correct values of z1. Applying PCA to the recovered subspace of z1 with rank 3, we receive a cube-like structure (since each of the three values can only be 1 or -1). The projections of query and key values clearly align onto this structure
Causal Interventions in QK Space
We also need to validate what the role of the recovered subspaces is. To do this, the authors choose a new random timestep to be the new target. Both these vectors are projected onto the latent subspace, and their coordinates are interchanged. We then recompute attention scores to see how much of the attention score shifts from the original key to the target key.
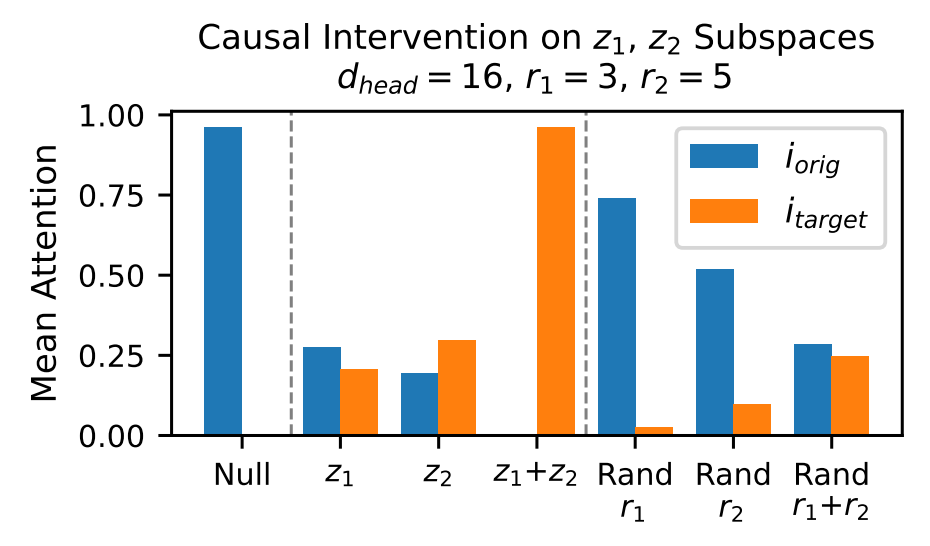
Here, we can see that when we only make changes to either z1 or z2, the attention shift is relatively small. However, when both are changed, attention moves entirely to the target value. This shows us that the attention is correlated with the values of z1 and z2, and interchanging them between keys has a large effect on how attention operates.
The authors also use random subspaces of the same dimensions as r1 and r2, in the last column, where we can see that it has minimal effect on the change in attention. This shows us that the attention is heavily dependent on the correct subspaces being found, and is not random.
Analysis of QK Features in LLMs
While the authors find evidence to prove that their QK decomposition works on the toy model, we still need to see if it works on real world models.
We only highlight one of the ways the authors analyzed LLMs, and leave the rest of the methods to the reader. However, this is sufficient to show how their toy attention model is applicable to real world LLMs
Filter Heads
In a separate paper, LLMs Process Lists With General Filter Heads, we find that LLMs possess specific attention heads that mirror filter functions. What this means is that some attention heads specialize on focusing only on specific features and ignore all the rest. As an example, below, the attention head only focuses on items that are fruits.

The authors identify these filter heads by creating similar prompts as above with at least five items per category, and query categories. They select the top three heads based on ratio of attention given to queried heads compared to all other items. Using the last token as the query vector, and key vectors for positive and negative QK covariances, they formulate
C + category: tokens belonging to the queried category c∗
C − category: tokens not belonging to the queried category.
When the visualisation for recovering latent subspaces is applied on Llama 3.1-8B, they observed clear clusters corresponding to each category, as well as symmetric alignment between query and key values belonging to the same category.
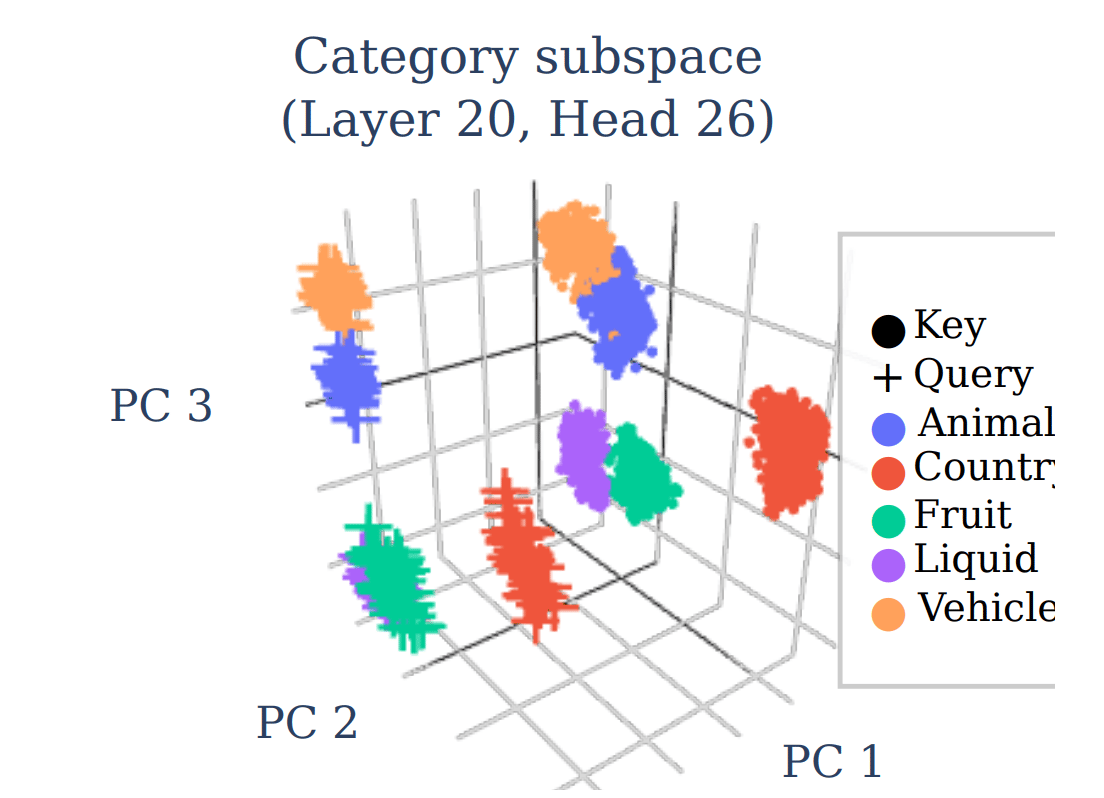
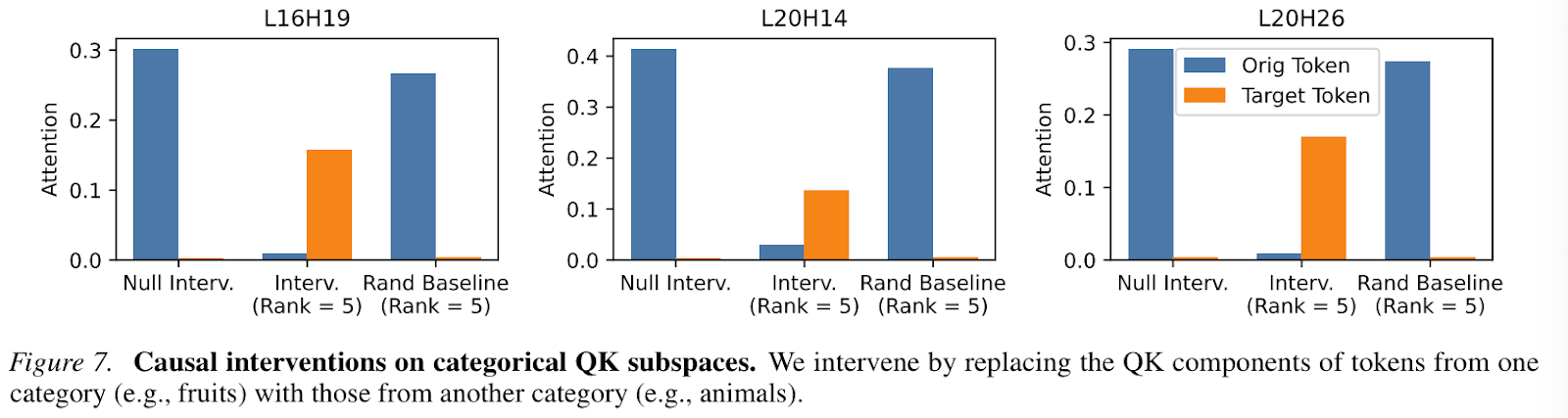
Similar results were found for the causal interventions on replacing QK components of tokens from one category to another, in tandem with the intervention analysis above. However, the authors note that the attention does not shift completely, highlighting that there might be some other underlying mechanisms operating in the QK space which they do not elaborate on.
Conclusion
This paper was an exciting read, offering a new lens into how attention mechanisms actually work. Most importantly, they provide a more general method to view QK subspaces in a human understandable format.
However, the authors also note some pitfalls. First, they highlight that when superposition occurs, the current model does not offer a clear path to understanding how often it occurs in real models and how we are supposed to interpret them. They additionally highlight that there may be other multidimensional features left undetected, and leave this to future work to analyze.
Another limitation of the current method is that we need to know what features to look for specifically in order to construct the negative and positive covariance matrices. The solution to this is creating a method to decompose QK spaces without any human intervention.
The challenges here are clear - the ranks of the features may vary significantly, so analyzing them with the above methods may not be possible. Another challenge is that even if we identify multiple QK components, their behaviours might be the same. In this case, how do we interpret each component?
Regardless, this area of research promises to offer exciting new avenues and mechanisms for understanding why attention works the way it does.
Awesome Machine Learning Summer Schools is a non-profit organisation that keeps you updated on ML Summer Schools and their deadlines. Simple as that.
Have any questions or doubts? Drop us an email! We would be more than happy to talk to you.
Reply