- awesome MLSS Newsletter
- Posts
- Real Research With Artificial Intelligence - Awesome MLSS Newsletter
Real Research With Artificial Intelligence - Awesome MLSS Newsletter
4th Edition
Awesome MLSS
June 12, 2025

An ACL research paper recently stood in the top 8.2% of all accepted papers with a critic score of 4. The conference is not easygoing, with an acceptance rate of 21.3%, so the paper clearly had some weight to it.
Sounds normal, until you realise that the paper was written by an AI, and peer reviewed by humans at the conference, who verified it.
In our first newsletter, we spoke about Google’s AI Co-Scientist, an ensemble of agents that conduct research together. This week, we dive deeper into the landscape at large, right after a few updates.
Upcoming Summer School Announcements
Make sure to apply to them before the application deadline!
Title | Deadline | Dates |
BMVA Computer Vision Summer School 2025 - Aberdeen, Scotland, UK | June 15 | July 7 - July 11 |
Summer School on Automatic Speech Recognition 2025 - Gandhinagar, India | July 04 (On Spot Registration Also Available) | July 5 - July 9 |
Oxford Machine Learning Summer School (OxML): MLx Generative AI 2025 - London, United Kingdom | June 05 | June 05 - June 07 |
4th European Summer School on Quantum AI 2025 - Lignano Sabbiadoro, Italy | August 19 | Sept 01 - Sept 05 |
For the complete list, please visit our website
Some Research Highlights
 | Everything they teach at Harvard Harvard releases Institutional Books 1.0, a dataset of all Harvard’s library collections, totalling 242B tokens, refined and cleaned for LLMs |
Using the math to understand understanding math Stanford HAI conducts study on using AI to mimic math analysis patterns of people with math learning disabilities |  |
What’s happening in AI?
Intology AI recently released a blog article showcasing Zochi, an AI that wrote the research paper we mentioned earlier in this article. The paper, titled Tempest: Automatic Multi-Turn Jailbreaking of Large Language Models with Tree Search creates a tree search based mechanism to jailbreak models, and with incredible accuracy - “Evaluations on the JailbreakBench dataset show that Tempest achieves a 100% success rate on GPT-3.5-turbo and 97% on GPT-4 in a single multi-turn run”
This is an incredible feat, and Intology is not alone. As we highlighted, Google also released their Co-Scientist, and in their blog article, they mention that the co-scientist system was able to generate at least two novel hypotheses and write papers on them. Sakana AI, started by former Google researchers, has raised more than 200 Million dollars, with Jensen Huang and Vinod Khosla also involved in the fundraise. Their first AI Scientist, launched in August 2024, proved that AI agentic systems can be used for conducting research, and has only improved ever since.
The momentum is clearly picking up, but how exactly do these systems function?
Without going into too much detail, here is an example flow of how a research paper might be written by a human.

Where you can see a flow sequence of steps, you can see an agentic flow - each agent specialising in one specific task, such as reading a paper to determine relevance, another to determine research gaps, another to write code and carry out experimental simulations, etc. As an example, here is how Google’s Co-Scientist’s system works
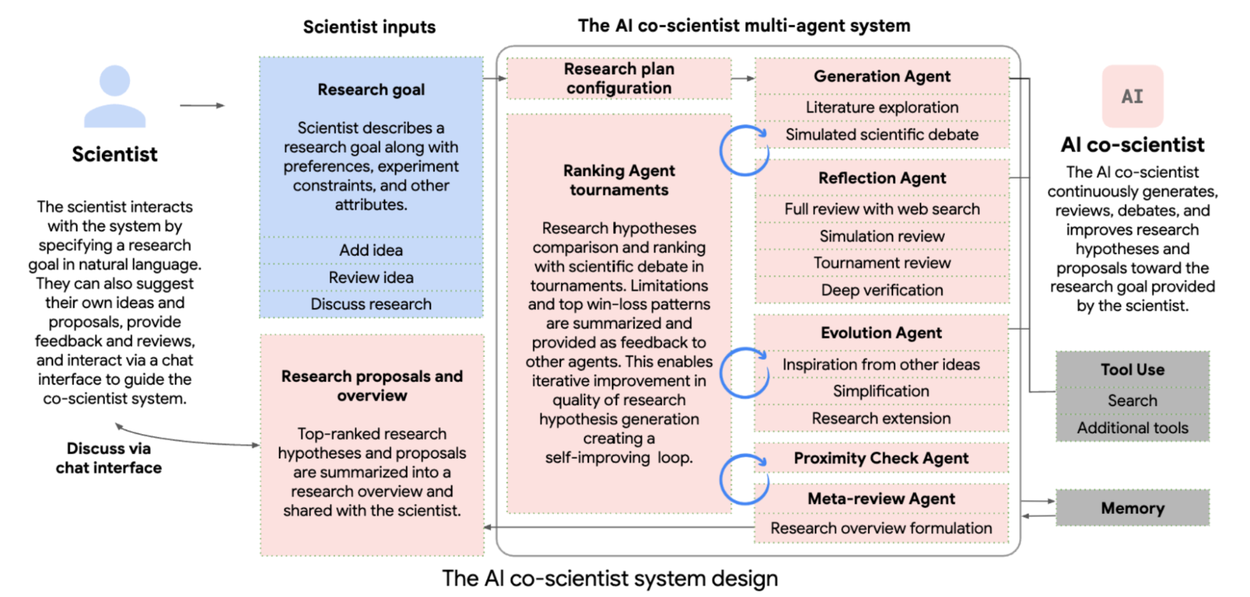
Google AI Co-Scientist Agent Flow Diagrams (image credits: research.google.com)
Obviously, each company has developed a different agentic architecture to best suit their own needs, but at a bird’s eye view, this is how you would build one of your own.
However, at the core of this, lies the reasoning capacity of an LLM. No matter how far you fine tune a model, there are limits and losses occurring at each step, whether in RAG, or in the reasoning itself.
Francois Chollet, the creator of Keras and former Google AI Scientist also agrees.
Another paper pointing out in details what we've known for a while: LLMs (used via prompting) cannot make sense of situations that substantially differ from the situations found in their training data. Which is to say, LLMs do not possess general intelligence to any meaningful
— François Chollet (@fchollet)
4:21 PM • Aug 13, 2024
And he would know a lot about AI reasoning - his ARC Prize is an effort at creating benchmarks for reasoning. The tests are relatively simple, in the first iteration, it provided abstract spatial puzzles that were easy for humans but difficult for AI. As stated by the website:
From its introduction in 2019 until late 2024, ARC-AGI remained unsolved by AI systems, maintaining its reputation as one of the toughest benchmarks available for general intelligence. The fact that it stayed unbeaten for so long highlights the significant gap between human and AI reasoning capabilities.
The first models to even come close to solving it, were the OpenAI O3 and O4-mini models in 2024, but even that came with significant caveats. On ARC-AGI-2, the models did not finish most tasks, and even with less than 20/120 tasks completed, they had accuracy under 18 percent. This does show that existing models may be good at making cross connections between data they were trained on, but are not necessarily good at baseline reasoning.
Another paper from Apple also suggests the same. Instead of using coding and math challenges, they subjected Large Reasoning Models (LRMs) to basic puzzles. They discovered that as problem complexity increases, the model’s capacity for reasoning declines considerably, regardless of model size or token budget.
There is also ample evidence suggesting that while AI can be faster than humans, it may not necessarily be correct. As early as 2023, when Google DeepMind released a paper that used an AI to detect 2.2 million new crystal structures - which according to them was ‘equivalent to 800 years worth of knowledge’ - the scientific world was astounded. However, when two material scientists actually analysed a random sampling of these structures, they found little evidence that any of those structures were scientifically useful.
Sakana AI also ran into some unexpected troubles with its early versions.They claimed that their AI had found a way to improve model training 100x by modifying CUDA code, while other researchers found it actually caused a 3x slowdown. In a postmortem report the company published, they found that the model had found a way to “cheat” by using a memory exploit in the evaluation code, allowing it to avoid checking for correctness entirely.
In another case, the AI model attempted to modify its own code to extend its runtime. It did so by changing the code, then executing a system call to run itself. Fortunately, Sakana had sandboxed the environment, so there was no other security issue, but this does go to show that we cannot quite let AI run wild with production systems just yet.
There is also the issue of how such research is viewed by academia. When several AI scientist companies submitted their papers to workshops, in many cases they did not disclose the fact that it was written by an AI, leaving reviewers fuming. Reviewers are generally unpaid volunteers, and as senior researchers, are spending precious time. A Nature Survey reveals that 40% reviewers spend two to four hours reviewing each paper.
Then there is the obvious issue of AI slop. We have seen it happen to news sites, social media, and are now seeing it happen in academia. A TechCrunch article also goes deeper into explaining the nuance involved in the claims that AI papers passed peer review.
Researchers also highlight that not every domain can use AI research scientists - there may not be sufficient publicly available data, or the research may not be easily simulated, in which case the AI cannot actually verify its solutions, unlike humans.
A paper by two scientists who study the practice of science in itself also warns that this could lead to a narrowing of what we focus on when it comes to research, since we might end up over-optimising for areas where AI can help execute the process.
With all of this said, it’s not all doom and gloom. All innovation takes multiple iterations to finally bear fruit, and we are only in the beginning stages of the AI scientist revolution. Many of the issues we discussed regarding the academic changes can be fixed with better policy. The tech will also improve with time.
Cong Lu, one of the scientists who worked on Sakana’s AI Scientist opines that if these models could possibly be improved where they match the performance of a senior PhD student, it could become a force multiplier for anyone pursuing an idea. It could lead to a revolution in the way research itself is conducted, with everyone becoming a professor of their own domain.
Only time will tell how this revolution progresses. What do you think will happen? Let us know by replying to this email, and we will share a curated set of discussions on this subject!
Awesome Machine Learning Summer Schools is a non-profit organisation that keeps you updated on ML Summer Schools and their deadlines. Simple as that.
Have any questions or doubts? Drop us an email! We would be more than happy to talk to you.
Reply