- awesome MLSS Newsletter
- Posts
- Reasoning about reasoning - Awesome MLSS Newsletter
Reasoning about reasoning - Awesome MLSS Newsletter
7th Edition
Awesome MLSS
August 18, 2025

Epistemology—the branch of philosophy that explores the nature, origins, and limits of knowledge—is, in a sense, the art of thinking about thinking.
One of the earliest moments linking this philosophical quest to machines came in 1947, when Alan Turing delivered a lecture in London. He spoke of “a machine that can learn from experience” and noted that “the possibility of letting the machine alter its own instructions provides mechanisms for this.”
From the very beginning, the goal of artificial intelligence was clear: to create machines that can reason. Fast-forward to today, and we have AI systems that surpass many humans at specific tasks—and are beginning to demonstrate genuine reasoning abilities.
In this issue, we’ll explore the fascinating realm of reasoning AI—what it means, how it’s built, and where it’s taking us next, right after a few quick updates.
Upcoming Summer School Announcements
Applications for most of the following summer schools are closing in the next 14 days. Make sure to apply to them before the application deadline!
Title | Deadline | Dates |
4th European Summer School on Quantum AI 2025 - Lignano Sabbiadoro, Italy | Aug 19 | Sep 1 - Sep 5 |
Aug 31 | Feb 02 - Feb 13, 2026 |
For the complete list, please visit our website
What’s happening in AI?
What does reasoning even entail? Honestly, this is still heavily debated within the scientific community. However, the fundamental idea is that reasoning, at least for AI models, is the ability to utilise its existing knowledge, and come up with the correct method for solving a problem.
Whether or not models can ‘think’ is a question better left to epistemologists or other branches of science - for our purposes, reasoning models solve a given problem with the correct rationale. Initially, it was assumed that with sufficient instruction based training data, this would be achievable, since the internal neurons of the model would eventually direct it to the correct path for thinking. However, anyone who has used the earlier versions of these models - say three year old ones - knows this is incorrect. As our demands for AI capability increase, so should their ability to reason.

Imagine you are in a coding interview, and the interviewer has given you a problem that clearly falls into a domain very similar to a different algorithm you already know about. Knowing that the other algorithm exists, is knowledge - we gain it through memorisation, through study, understanding. Applying that baseline knowledge to a new setting, is where we are reasoning.
However, even as we reason, we tend to first come up with multiple hypotheses, and see which one could possibly take us closer to the solution. This is the key intuition behind training reasoning models - driving them closer to multiple hypotheses, determining which one might work, and then solving the problem. Let us now take a look at the methods.
Methods for Reasoning
Inference Time Scaling/Test-Time compute scaling
If you have used any of the o-series models by OpenAI, that offer reasoning abilities, you would have noticed that the model ‘thinks’ for some time, maybe seconds, or minutes. The reason this happens is because as we mentioned before, first, the model creates multiple pathways to solve and reason over the solution, and then chooses the path that best suits the situation.
In fact, Google published a paper in 2024, Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters, which found that scaling test time compute via various strategies might actually prove to be much more effective than scaling model size.
If you are interested in more strategies to improve Inference Time Scaling, Sebastian Raschka has written a beautiful article
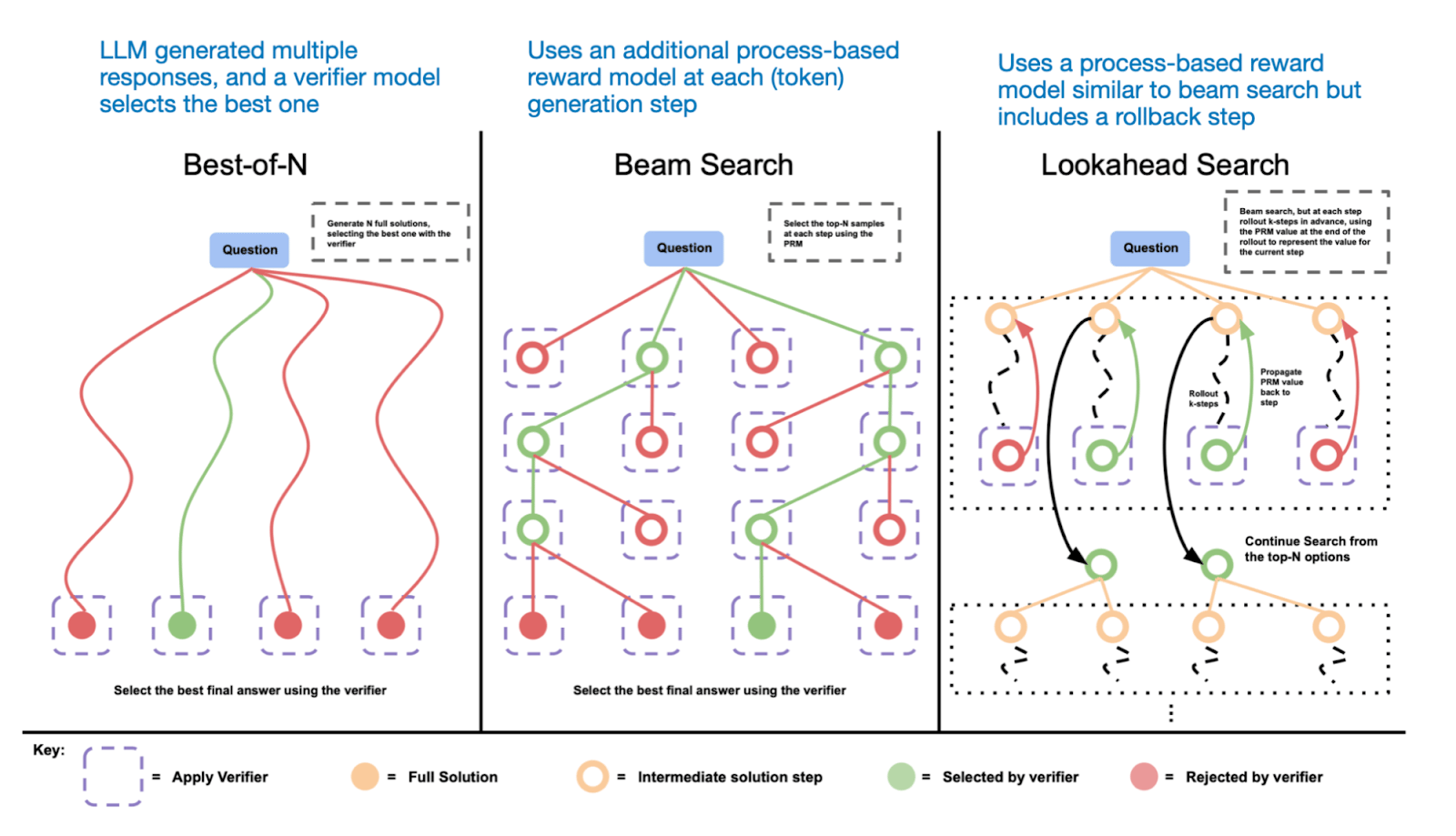
Img source: https://arxiv.org/abs/2408.03314
Pure Reinforcement Learning/Train Time Scaling
Strictly speaking, Train-Time Compute Scaling would entail training on more, or better refined data. We specifically want to speak about Pure Reinforcement Learning, but the same procedure can be applied via RL + SFT or Pure SFT as well.
While many other models choose the above inference time scaling methods, DeepSeek R1 presented a unique approach. Instead of making the model create multiple hypotheses and then work the correct path, they trained the model to reason ‘internally’ in a single pass, and trained it on this objective using reinforcement learning from scratch.
Now, there are two important things to note here.
The first is that this approach was successful. Despite not scaling inference time compute, DeepSeek R1 was still performant against other reasoning models of comparable sizes of the same era.
The second, is that with these emergent reasoning capabilities arising ‘internally’, we can still use inference time scaling on such models, potentially improving accuracy and reasoning capabilities even more. Inference time scaling is really more a function on the application level, and not on the model level itself, even though there is some element of fine tuning based on inference time scaling chain of thought data.
Dataset Generation
Above, we saw the broad categories of how reasoning models are trained to reason step by step. Data, however, is what decides what the model is capable of. How exactly are we generating data for reasoning?
In 2023, Google released a paper Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. This paper helped find the optimal path of prompting to find correct answers, specifically a method called Chain Of Thought Prompting. Even with non reasoning based models, they saw a massive improvement in output quality, especially when it came to logical questions. If you’d like to explore the history of CoT further, here is an excellent survey paper
CoT essentially performs the same task as we had mentioned before - it helps guide the LLM into a region of correctness by forcing it to think step by step, breaking down a big problem into smaller, individually verifiable chunks.
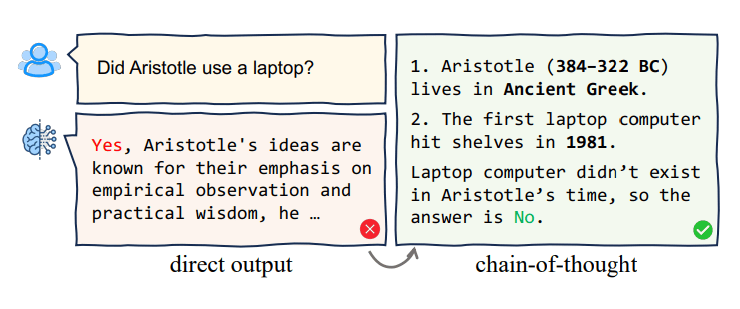
Img Source: https://arxiv.org/pdf/2309.15402
A key point to note here is verifiability. While we can easily verify singular factual statements, it often gets hard to verify subjective hypotheses - for example, are cats truly evil? We will never have a singular answer to this.
Fortunately, the world of AI is currently more focused on solving mathematical and coding related problems. The key benefit with math and code, is that we can immediately determine whether or not a solution is correct, and the process too can be independently verified. This is especially important when we are using reinforcement learning, since you can in theory create an infinitely large dataset of coding or math related problems for rewards.
The unfortunate fact is that we have very little information on how datasets were curated for the state of the art closed source models, since this information is proprietary. However, there are some open source labs who have revealed their curation methods.
DeepSeek R1’s training in fact largely utilised a largely synthetically generated dataset, which was created by prompting DeepSeek R1-Zero, and then using human verifiers to verify the prompts. For code verification, they utilised LeetCode’s verification system. Despite the synthetic nature of the dataset, we have all seen the quality of outputs from the model.
NovaSky’s T1 model was trained by following the traces of QwQ-32B preview, reformatted with GPT-4o-mini for better usage in training. They generated 17k samples this way.
So what does the future look like?
So far, there is ample evidence that models trained with reasoning capacity are considerably more performant for highly logical problems that demand step by step breakdowns.
This is especially important for both scientific tasks such as mathematics, biology, programming, or business related tasks, where baseline logic is important, but so is correctness. Even the earliest reasoning models sometimes outperform present LLMs trained with only instruction fine tuning.
However, there are still some ongoing research questions, which is not surprising since we are still in the beginning stages of the reasoning model era.
One paper by Apple which we have highlighted in previous letters has sort of gone ‘viral’, or at least as viral as a research paper can be. The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity highlights some key issues with our understanding of reasoning - it shows that reasoning based models, while more performant than their ancestors, still fail to answer any questions that have a high complexity level. This makes them in a sense “better” aligned to reason, but begs the question - are these models actually even reasoning?
Another paper, Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? seems to agree on the direction above. In fact, it directly challenges the idea that reinforcement learning is really eliciting the kind of reasoning we expect, with base models, and in some cases even distilled models having better reasoning capabilities.
Well, yes, there are still many open research challenges, but the future certainly looks promising. The promise that we once lay in AI to reason and think the way humans do, seems to be coming closer to being reality.
Awesome Machine Learning Summer Schools is a non-profit organisation that keeps you updated on ML Summer Schools and their deadlines. Simple as that.
Have any questions or doubts? Drop us an email! We would be more than happy to talk to you.
Reply